Why use Pro Voice Cloning?
A Professional Voice Clone (PVC) is a voice that uses a fine-tune of our TTS model on your data, which allows it to create an almost exact replica of the voice it hears, including accent, speaking style, and audio quality. Compared to Instant Voice Cloning, Pro Voice Cloning can capture the exact nuances of your hours of studio-quality audio voice data.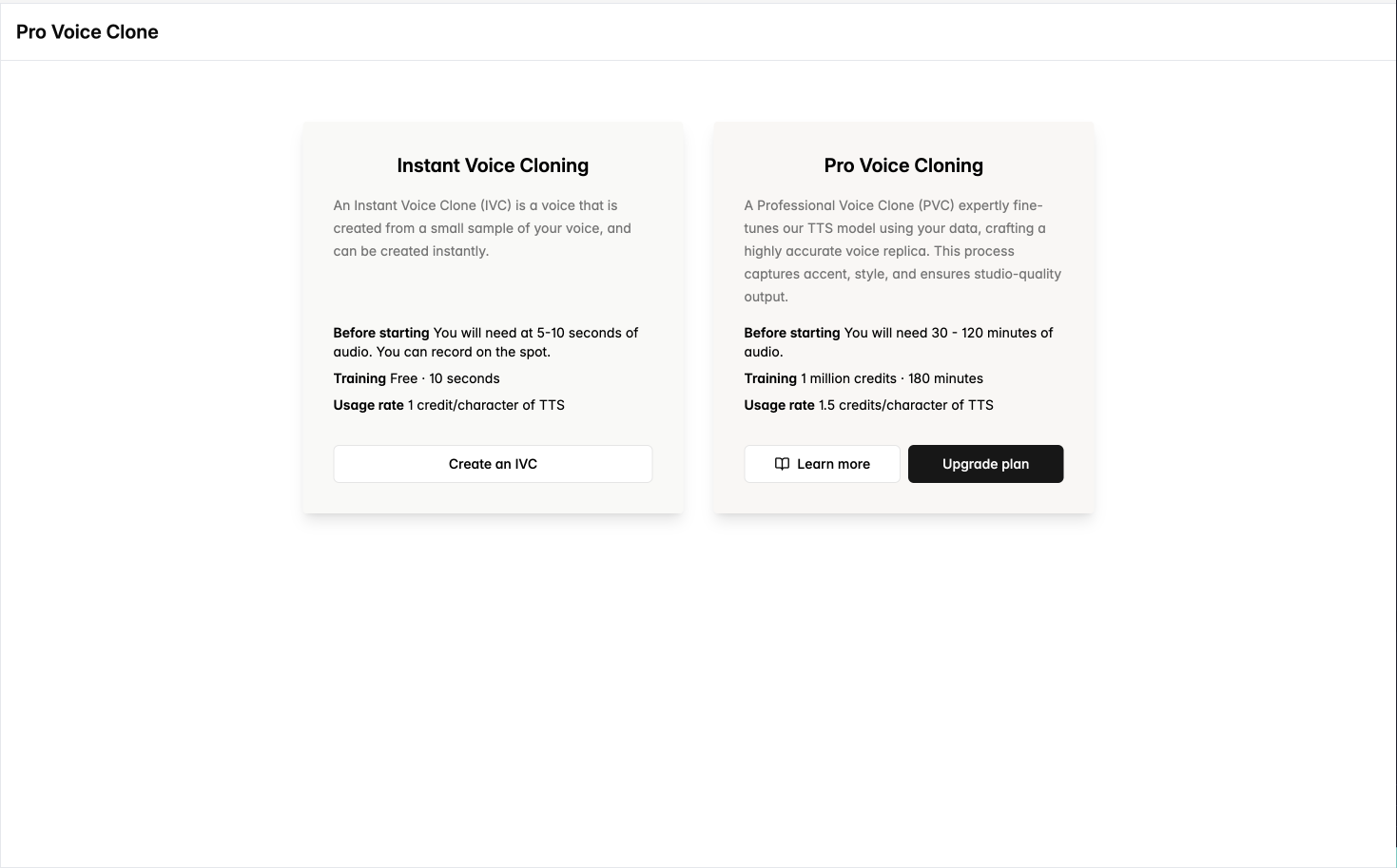
Overview
Pro Voice Cloning is available for anyone with a Cartesia subscription of Startup or higher. It allows you to create highly accurate voice clones by leveraging a larger amount of data compared to instant cloning.
When you create a Pro Voice Clone, Cartesia first fine-tunes a model on your data, then creates Voices from selected clips of your data. These Voices are tied to the fine-tuned model and will be automatically used with these Voices for text-to-speech.
Creating a PVC via the Playground
You can visit the Pro Voice Clone page on our playground to create a PVC. You can also find all your PVCs and their statuses (i.e. Draft, Failed, Training, Completed) here.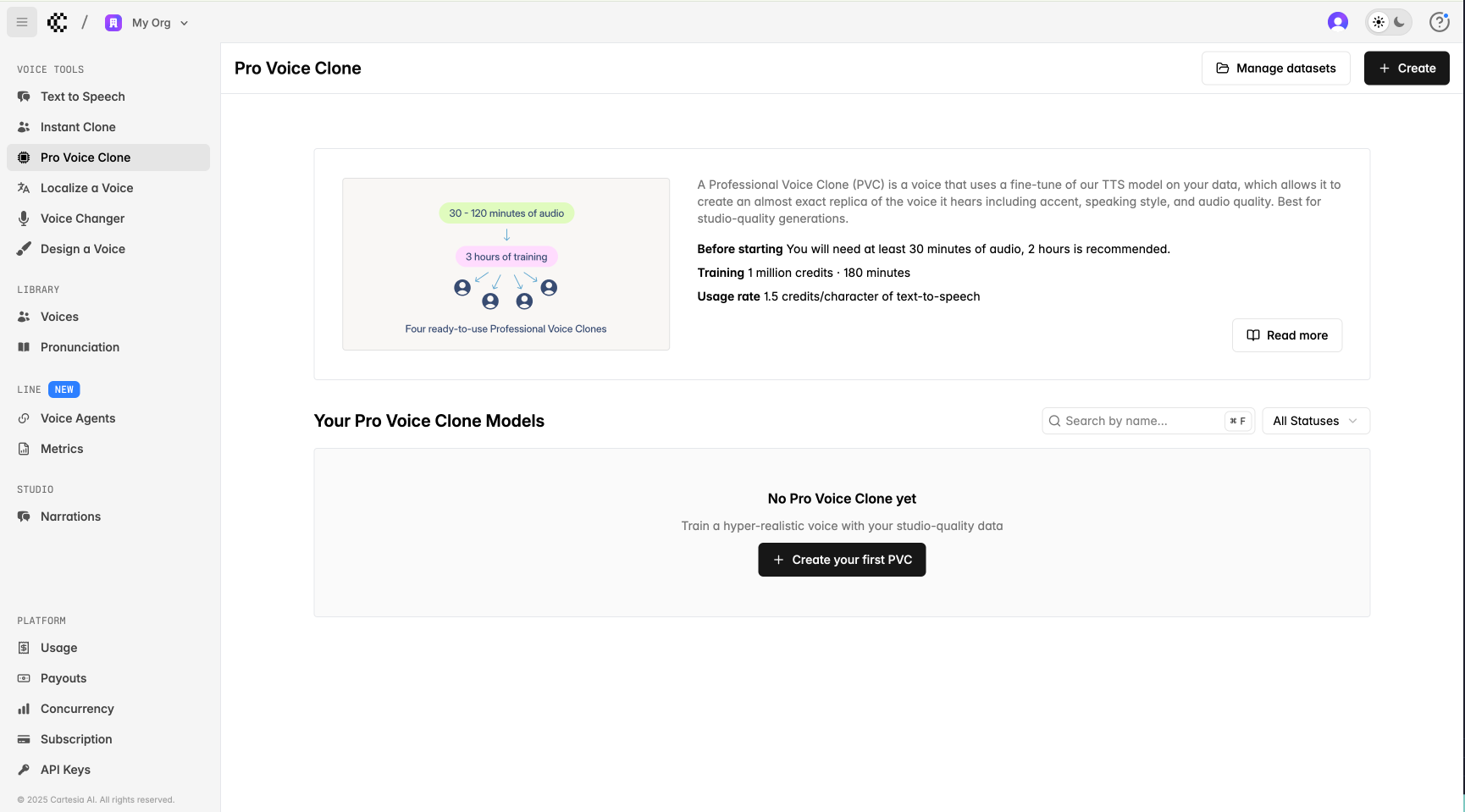
1
Prepare Data
Fill out the form to create a Pro Voice Clone, including language and accent.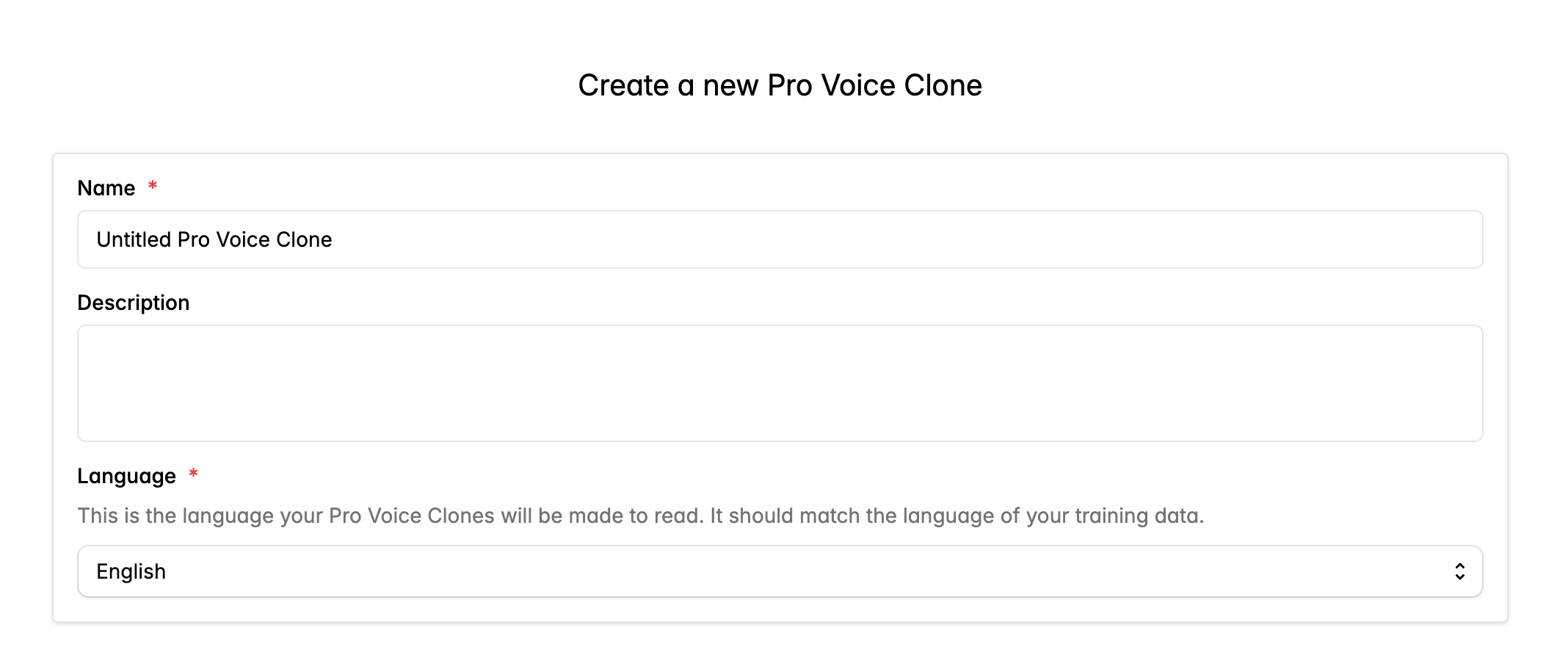
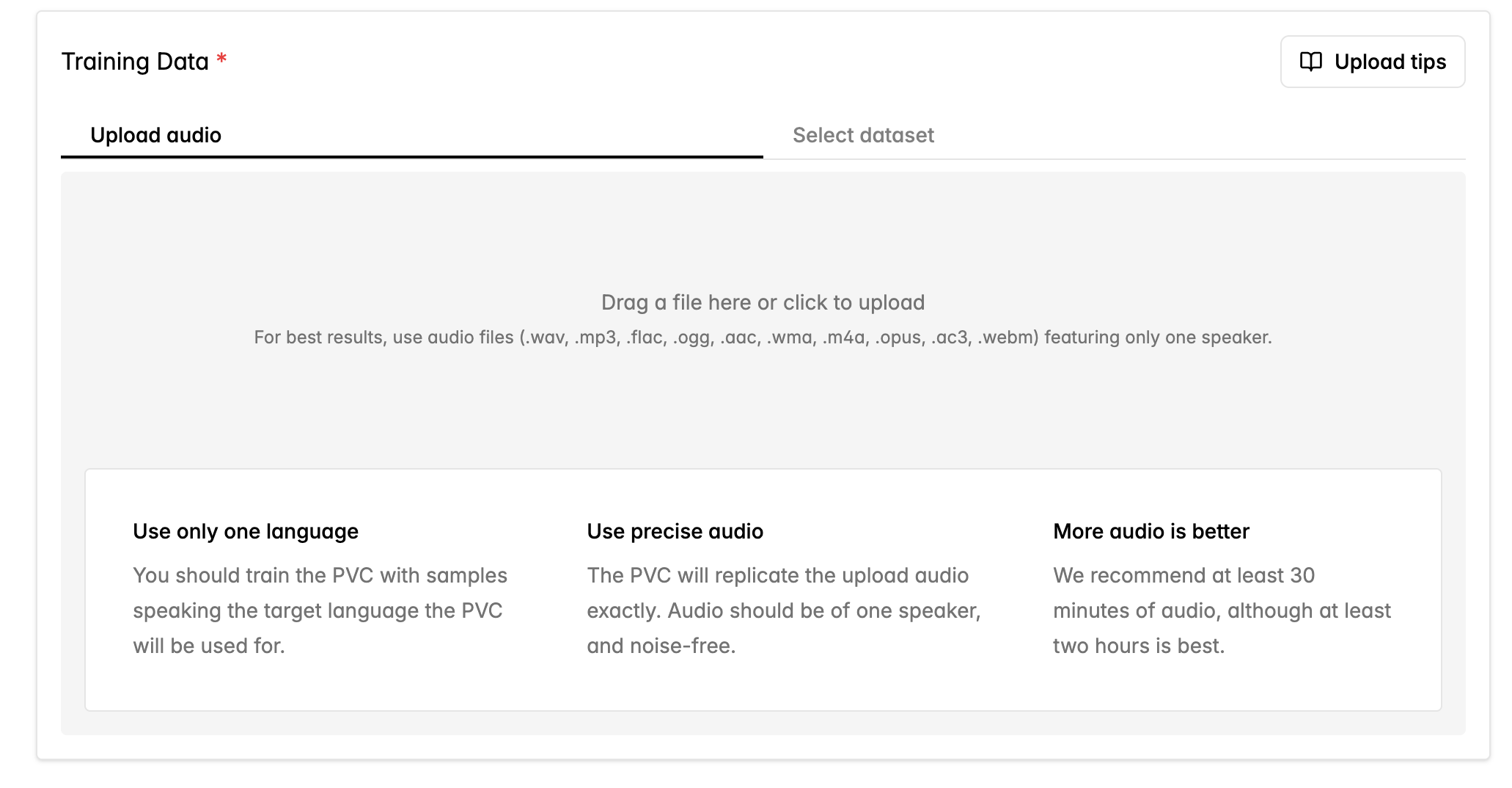
- .wav
- .mp3
- .flac
- .ogg
- .oga
- .ogx
- .aac
- .wma
- .m4a
- .opus
- .ac3
- .webm
2
Train Model
Training should take 3 hours to complete. You’ll only be charged if the training is successful. If training fails, you can click the
Re-attempt Training button to try again or contact support if the failures persist.3
Test Voices
Once training is complete, we’ll automatically create four Voices based on different source audio clips from your dataset. These Voices are internally linked to your fine-tuned model, which will be used when you specify the model ID of the fine-tuned model in your requests.The Voices are also available in the Voice Library under My Voices and can be used through the API.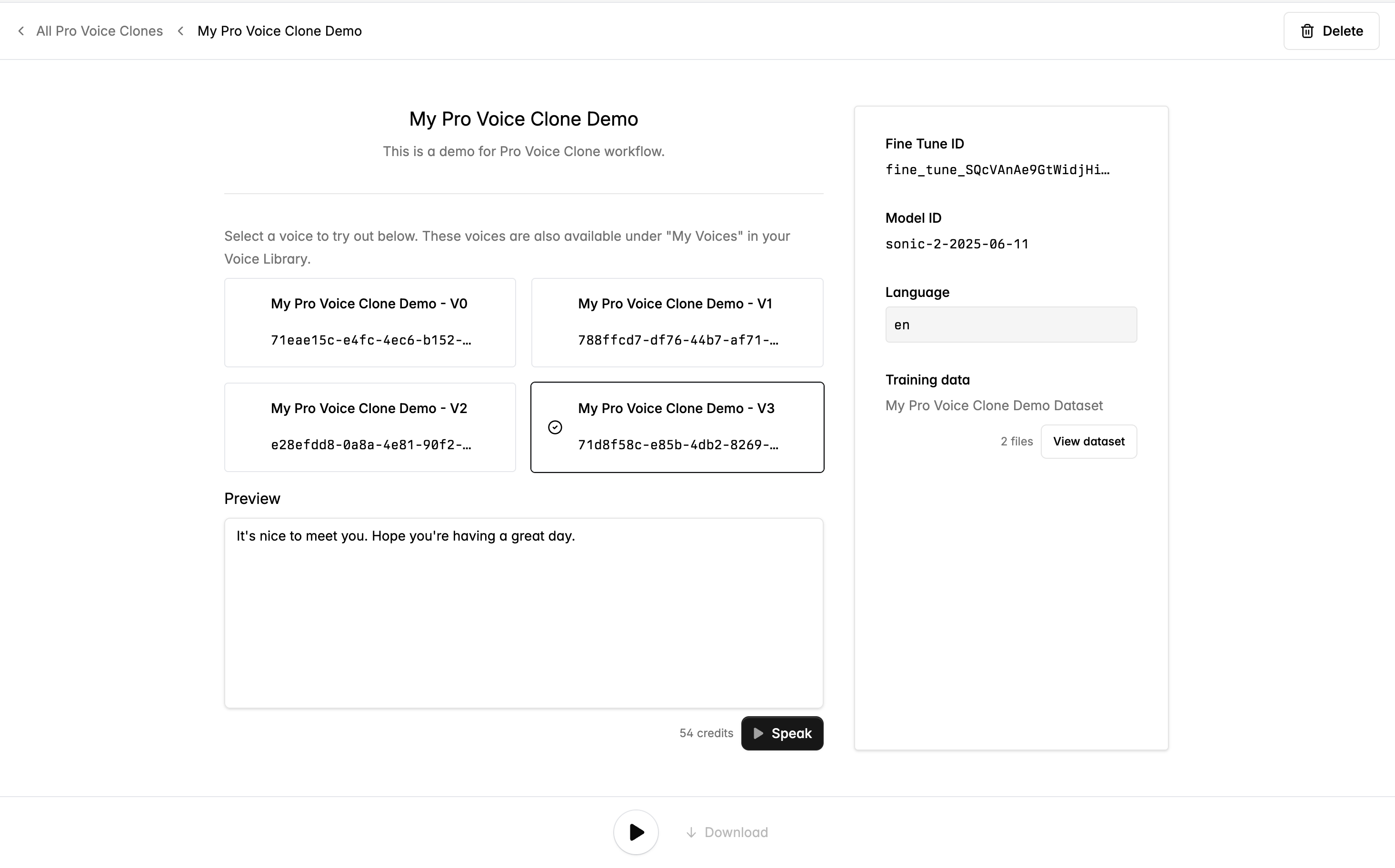
model-id. PVCs will not automatically be updated for future base models, and will need to be retrained on each new base model.
Retraining a new fine-tuned model with new data or the latest base model will again cost 1M credits.Creating a PVC via the API
You can also create PVCs programmatically via the API. Some key endpoints are:- Datasets: Create (holds your training data)
- Datasets: Upload file (uploads your training data)
- Fine Tunes: Create (creates a fine-tuned model)
- Fine Tunes: List Voices (PVCs that you can use for generating audio)
Prerequisites
- You have a Cartesia API key (export it as
CARTESIA_API_KEY).- You have at least 1M credits on your account.
- You have a folder called
samples/with one or more.wavfiles.