This guide will cover how input streaming works from the perspective of the TTS model. If you just want to implement input streaming, see the WebSocket API reference, which implements continuations using contexts.The Python and TypeScript SDKs handle the
continue flag for you: ctx.push() sends each chunk with continue: true, and ctx.no_more_inputs() sends continue: false. See the WebSocket continuations example for working code.Continuations
Continuations are generations that extend already generated speech. They’re called continuations because you’re continuing the generation from where the last one left off, maintaining the prosody of the previous generation. If you don’t use continuations, you get sudden changes in prosody that create seams in the audio.Prosody refers to the rhythm, intonation, and stress in speech. It’s what makes speech flow naturally and sound human-like.
Hello, my name is Sonic.It's very niceto meet you.
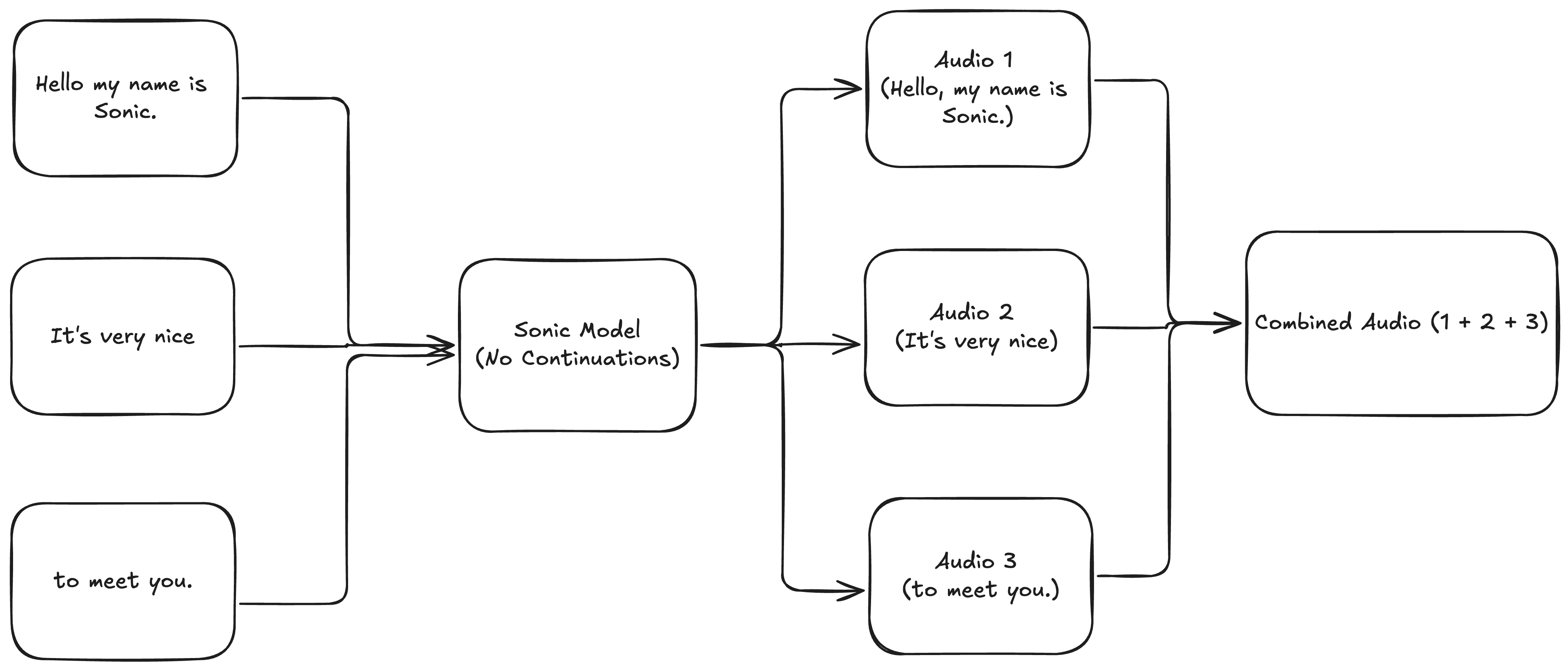
Figure 1: Generate transcripts independently & stitch them together.
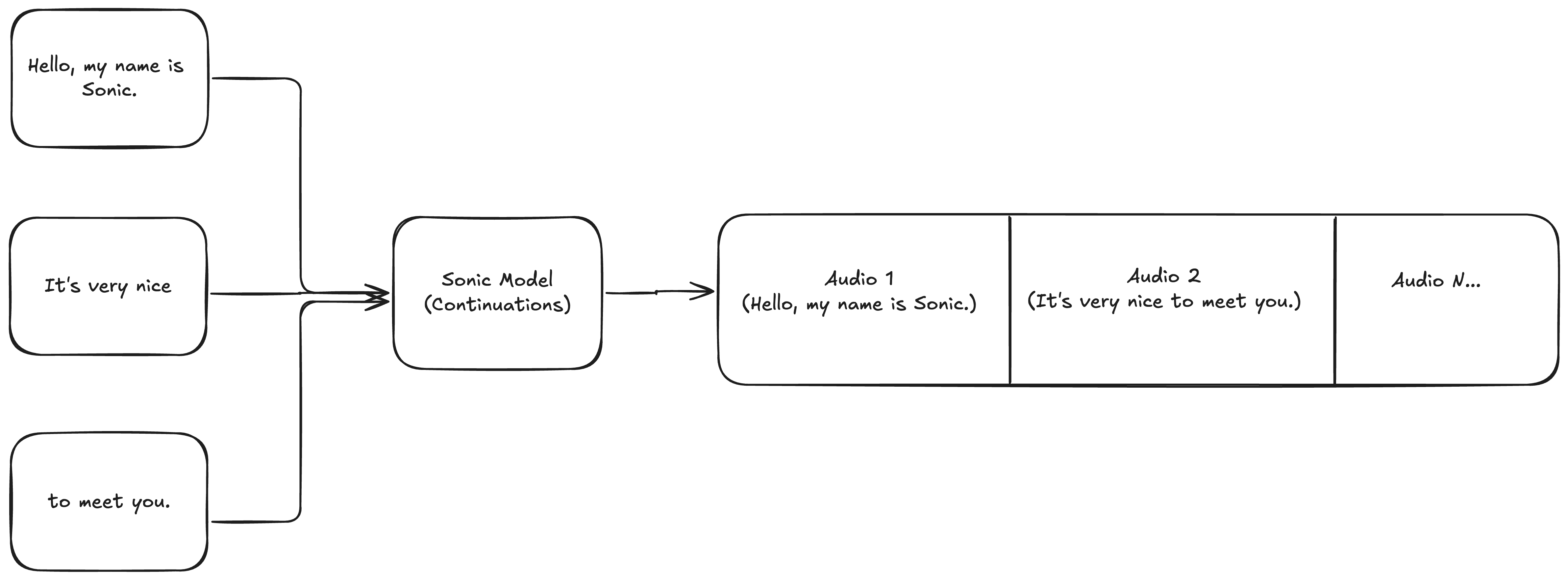
Figure 2: Generate transcripts using continuations.
You can scale up continuations to any number of inputs. There is no limit.
Caveat: Streamed inputs should form a valid transcript when joined
This means that"Hello, world!" can be followed by " How are you?" (note the leading space) but not "How are you?", since when joined they form the invalid transcript "Hello, world!How are you?".
In practice, this means you should maintain spacing and punctuation in your streamed inputs.
Automatic buffering with max_buffer_delay_ms
When streaming inputs from LLMs word-by-word or token-by-token, we buffer text until the optimal transcript length for our model. The default buffer is 3000ms, if you wish to modify this you can use the max_buffer_delay_ms parameter, though we do not recommend making this change.
How it works
When set, the model will buffer incoming text chunks until it’s confident it has enough context to generate high-quality speech, or the buffer delay elapses, whichever comes first. Without this buffer, the model would immediately start generating with each input, which could result in choppy audio or unnatural prosody if inputs are very small (like single words or tokens).Configuration
- Range: Values between 0-5000ms are supported
- Default: 3000ms
- you have custom buffering client side, in which case you can set this to 0
- you have choppiness even at 3000ms, in which case you can try a higher value
max_buffer_delay_ms=3000: ['Hello', 'my name', 'is Sonic.', "It's ", 'very ', 'nice ', 'to ', 'meet ', 'you.']