このガイドでは、TTS モデルの観点から入力ストリーミングの仕組みを説明します。入力ストリーミングを実装したいだけの場合は、contexts を使用して継続を実装している WebSocket API リファレンス を参照してください。Python と TypeScript の SDK は
continue フラグを自動で処理します。ctx.push() は各チャンクを continue: true で送信し、ctx.no_more_inputs() は continue: false を送信します。動作するコードは WebSocket continuations の例 を参照してください。継続
継続とは、すでに生成された音声を延長する生成のことです。前の生成が終了したところから生成を継続し、前の生成の プロソディ を維持するため、継続と呼ばれます。 継続を使わない場合、プロソディが突然変化し、音声に継ぎ目が発生します。プロソディとは、音声のリズム、イントネーション、ストレスを指します。音声を自然に流れさせ、人間らしく聞こえさせる要素です。
Hello, my name is Sonic.It's very niceto meet you.
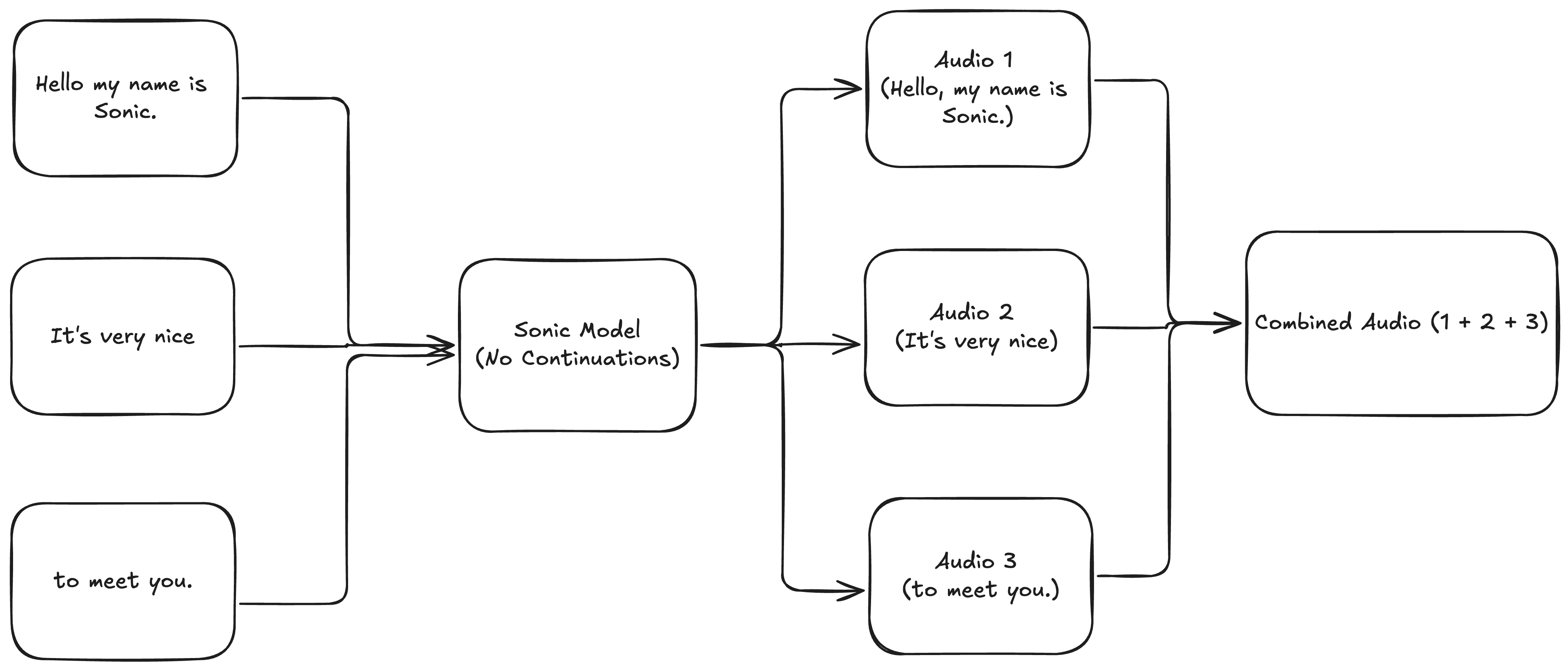
図 1: 原稿を個別に生成して結合する。
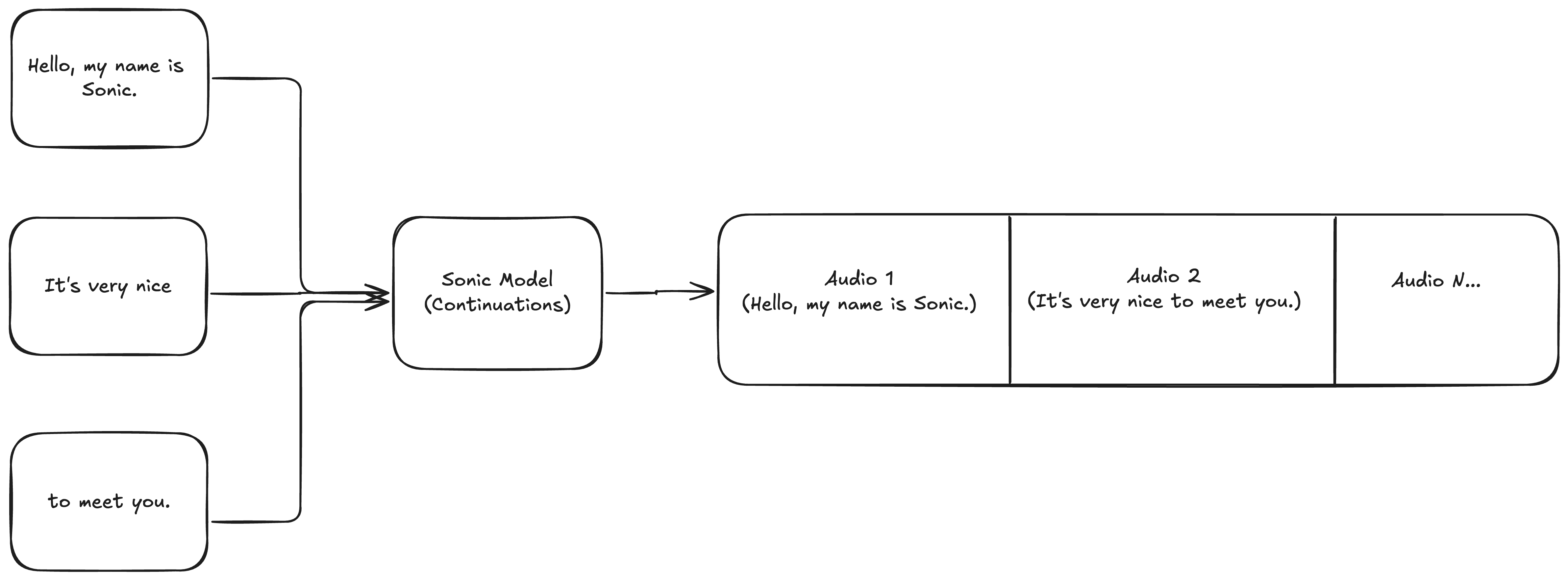
図 2: 継続を使って原稿を生成する。
継続は任意の数の入力にスケールできます。上限はありません。
注意点: 結合したときに有効な原稿になる必要がある
これは、"Hello, world!" の後に " How are you?" (先頭の空白に注意) を続けることはできますが、"How are you?" を続けることはできないということです。結合すると "Hello, world!How are you?" という無効な原稿になるためです。
実際には、ストリームする入力で空白と句読点を維持する必要があります。
max_buffer_delay_ms による自動バッファリング
LLM から単語ごとまたはトークンごとに入力をストリーミングする場合、モデルにとって最適なテキストの長さになるまでバッファリングします。デフォルトのバッファは 3000ms です。これを変更したい場合は max_buffer_delay_ms パラメータを使えますが、この変更は推奨しません。
仕組み
設定すると、モデルは高品質な音声を生成するのに十分なコンテキストがあると確信するか、バッファ遅延が経過するか、いずれか早い方まで入力テキストチャンクをバッファリングします。 このバッファがない場合、モデルは各入力ですぐに生成を開始するため、入力が非常に小さい (単語やトークン単位) と、音声がぶつ切りになったり、プロソディが不自然になったりする可能性があります。設定
- 範囲: 0-5000ms の値がサポートされています
- デフォルト: 3000ms
- クライアント側でカスタムバッファリングを行っている場合は、0 に設定できます。
- 3000ms でもぶつ切り感がある場合は、より高い値を試してください。
max_buffer_delay_ms=3000 で次の原稿を試してみましょう: ['Hello', 'my name', 'is Sonic.', "It's ", 'very ', 'nice ', 'to ', 'meet ', 'you.']