> ## Documentation Index
> Fetch the complete documentation index at: https://docs.cartesia.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Pro Voice Clone
## なぜ Pro Voice Cloning を使うのか?
Professional Voice Clone (PVC) は、あなたのデータで TTS モデルをファインチューニングして作成される音声で、アクセント、話し方、音質を含めて聞き取ったボイスをほぼ忠実に再現できます。
[Instant Voice Cloning](/build-with-cartesia/capability-guides/clone-voices) と比較して、Pro Voice Cloning は数時間に及ぶスタジオ品質の音声データの細かなニュアンスまで捉えることができます。
 ## 概要
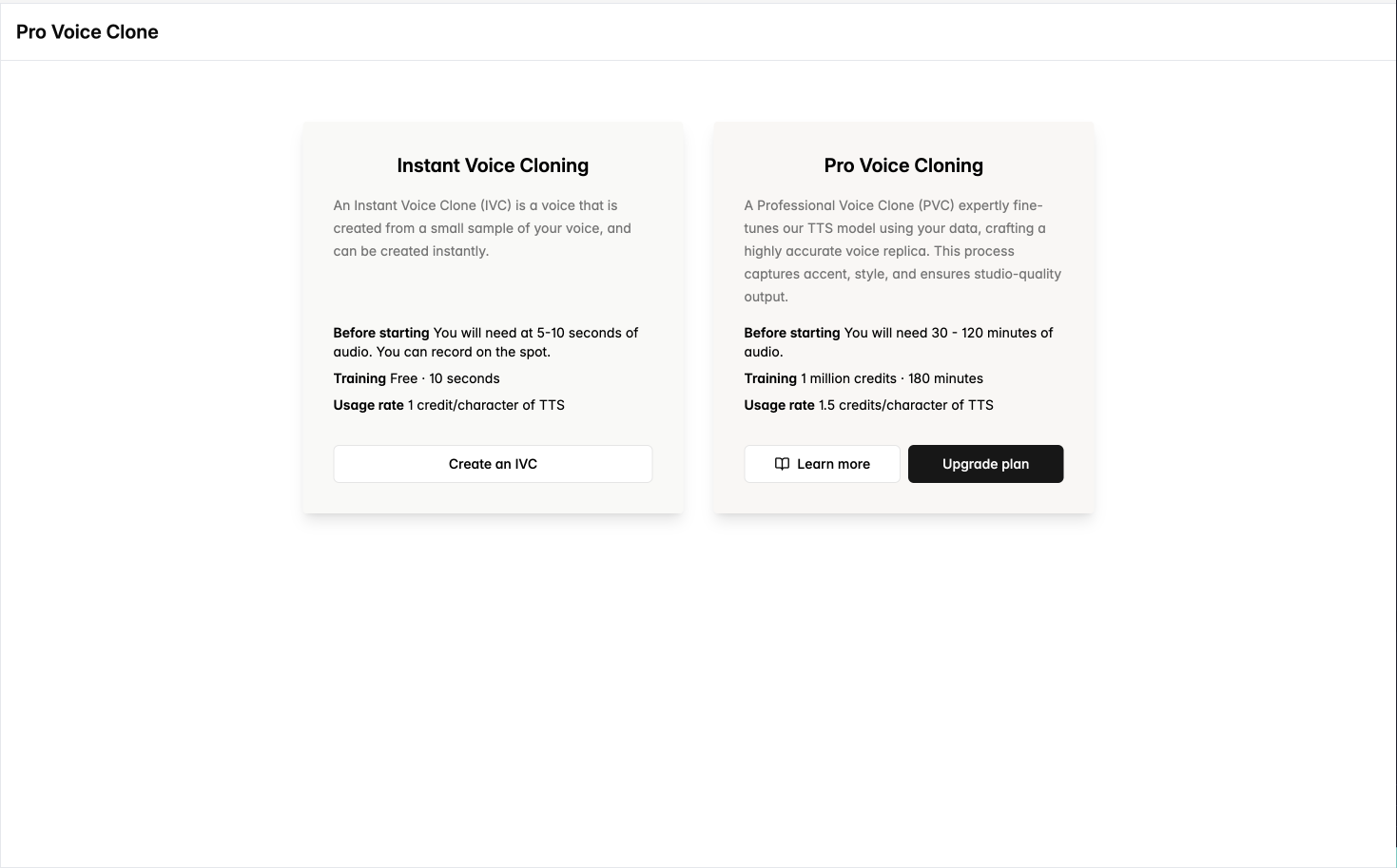
Pro Voice Cloning は、Startup プラン以上の Cartesia サブスクリプションをお持ちの方にご利用いただけます。インスタントクローンと比べてより多くのデータを活用し、非常に精度の高いボイスクローンを作成できます。
| 機能 | 必要な音声データ | 価格: 作成時のコスト | 価格: TTS 使用時のコスト |
| ------------------- | -------- | --------------- | ------------------- |
| Instant Voice Clone | 10 秒 | 無料 | 1 文字あたり 1 credit |
| Pro Voice Clone | 30 分 | 成功時に 1M credits | 1 文字あたり 1.5 credits |
Pro Voice Clone を作成すると、Cartesia はまずあなたのデータでモデルをファインチューニングし、その後、データから選ばれたクリップをもとにボイスを作成します。これらのボイスはファインチューニング済みモデルに紐づけられ、テキスト読み上げの際にそれらのボイスとともに自動的に使用されます。
## 概要
Pro Voice Cloning は、Startup プラン以上の Cartesia サブスクリプションをお持ちの方にご利用いただけます。インスタントクローンと比べてより多くのデータを活用し、非常に精度の高いボイスクローンを作成できます。
| 機能 | 必要な音声データ | 価格: 作成時のコスト | 価格: TTS 使用時のコスト |
| ------------------- | -------- | --------------- | ------------------- |
| Instant Voice Clone | 10 秒 | 無料 | 1 文字あたり 1 credit |
| Pro Voice Clone | 30 分 | 成功時に 1M credits | 1 文字あたり 1.5 credits |
Pro Voice Clone を作成すると、Cartesia はまずあなたのデータでモデルをファインチューニングし、その後、データから選ばれたクリップをもとにボイスを作成します。これらのボイスはファインチューニング済みモデルに紐づけられ、テキスト読み上げの際にそれらのボイスとともに自動的に使用されます。
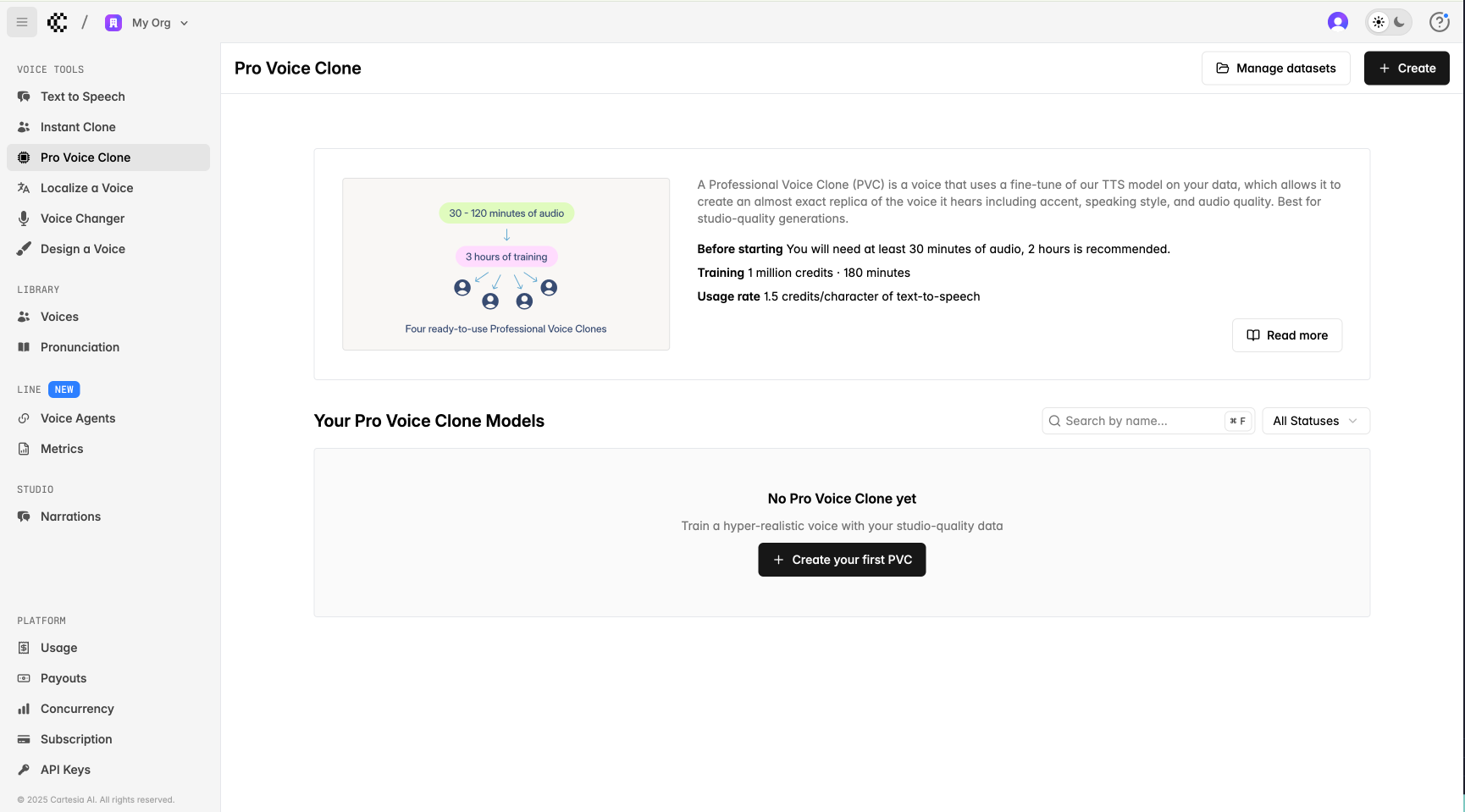
 ## プレイグラウンドから PVC を作成する
プレイグラウンドの [Pro Voice Clone](https://play.cartesia.ai/pro-voice-cloning) ページで PVC を作成できます。ここでは、ご自身のすべての PVC と、そのステータス (Draft、Failed、Training、Completed など) も確認できます。
## プレイグラウンドから PVC を作成する
プレイグラウンドの [Pro Voice Clone](https://play.cartesia.ai/pro-voice-cloning) ページで PVC を作成できます。ここでは、ご自身のすべての PVC と、そのステータス (Draft、Failed、Training、Completed など) も確認できます。
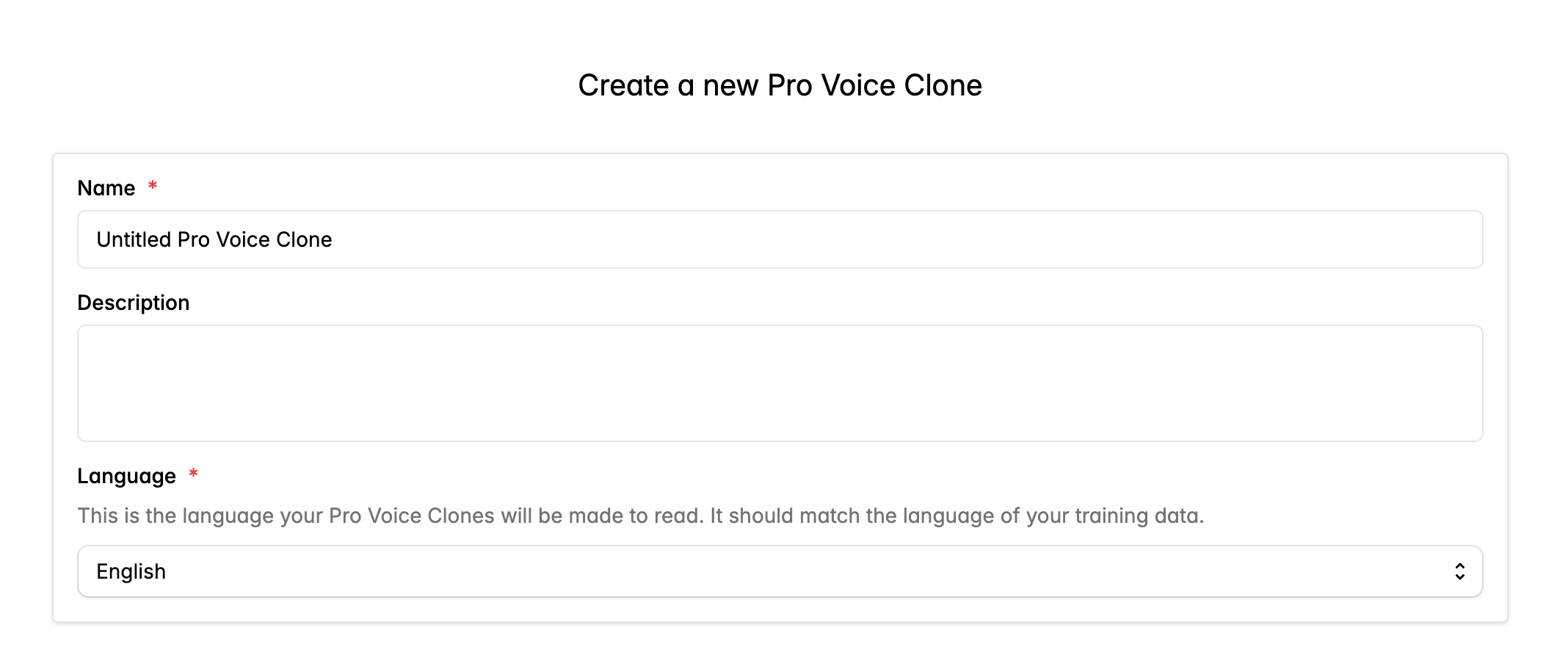
 フォームに記入して Pro Voice Clone を作成します。
フォームに記入して Pro Voice Clone を作成します。
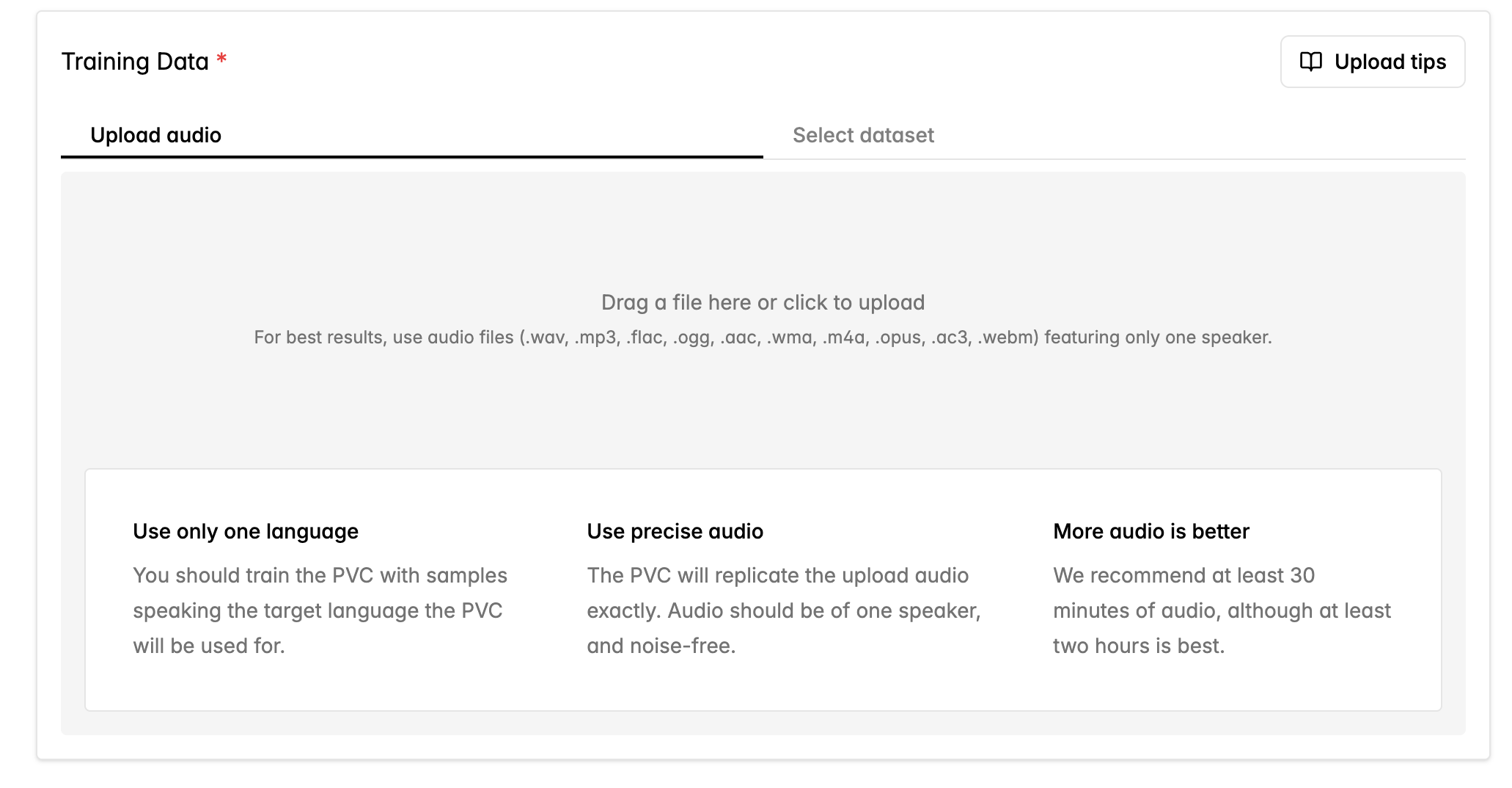
 次に、トレーニングに使用したいすべての音声ファイルをアップロードします。複数のファイルを一度にアップロードできます。ファイルは次のいずれかの音声形式である必要があります。
* .wav
* .mp3
* .flac
* .ogg
* .oga
* .ogx
* .aac
* .wma
* .m4a
* .opus
* .ac3
* .webm
Pro Voice Clone には最低 30 分の音声が必要ですが、品質と労力のバランスを最適化するには 2 時間の音声を推奨します。Pro Voice Clone はアップロードしたデータに忠実に近づくため、背景ノイズ、音量、音声の品質の点で、聞こえ方が望ましい状態になっていることを確認してください。
一般的に、クローンしたい話者だけが含まれる音声をアップロードするほうが良い結果が得られます。複数話者の音声はクローンの品質を損なう可能性があります。
次に、トレーニングに使用したいすべての音声ファイルをアップロードします。複数のファイルを一度にアップロードできます。ファイルは次のいずれかの音声形式である必要があります。
* .wav
* .mp3
* .flac
* .ogg
* .oga
* .ogx
* .aac
* .wma
* .m4a
* .opus
* .ac3
* .webm
Pro Voice Clone には最低 30 分の音声が必要ですが、品質と労力のバランスを最適化するには 2 時間の音声を推奨します。Pro Voice Clone はアップロードしたデータに忠実に近づくため、背景ノイズ、音量、音声の品質の点で、聞こえ方が望ましい状態になっていることを確認してください。
一般的に、クローンしたい話者だけが含まれる音声をアップロードするほうが良い結果が得られます。複数話者の音声はクローンの品質を損なう可能性があります。
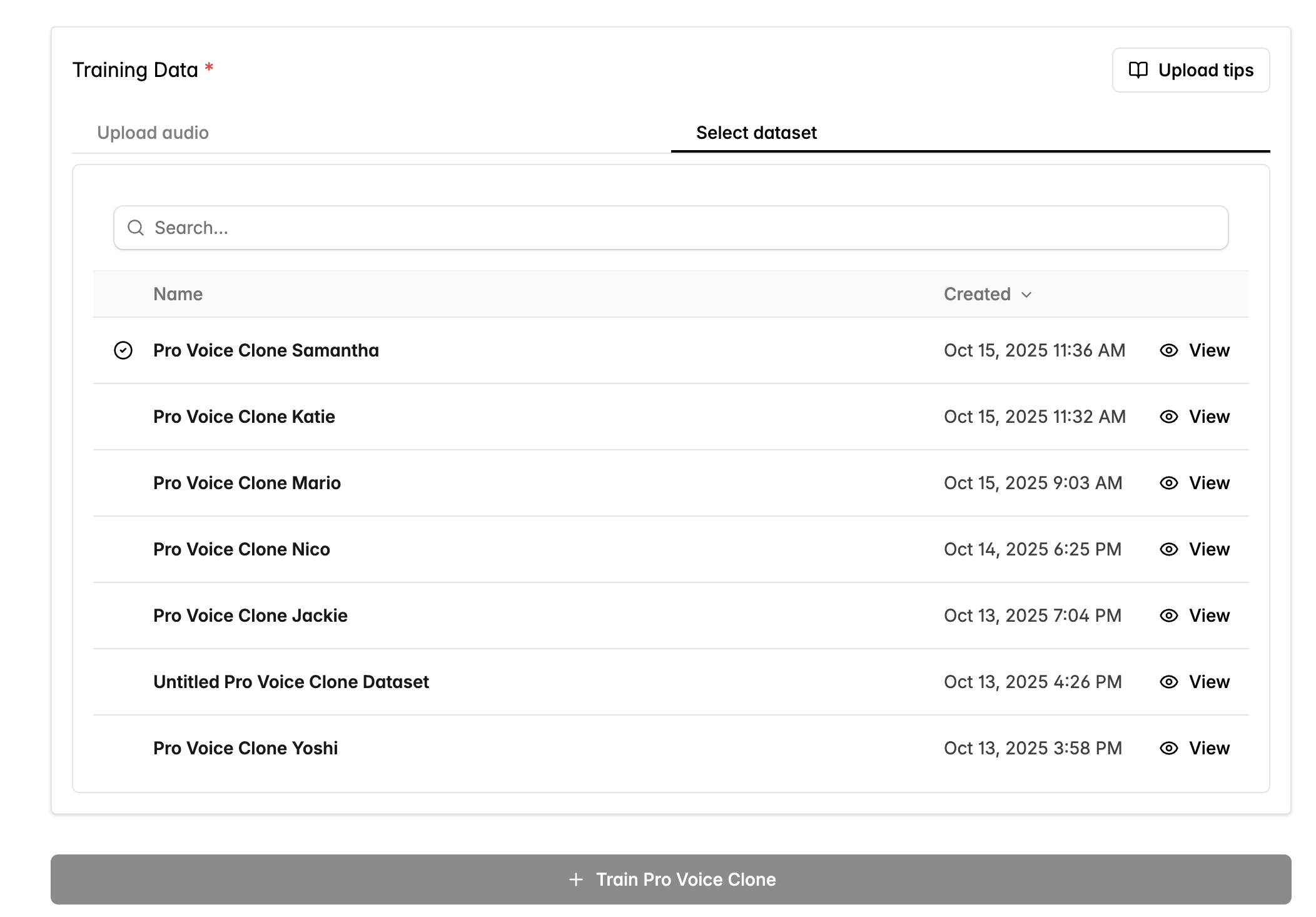
 過去の Pro Voice Clone のデータを再利用する場合は、**Select dataset** タブに切り替えて、以前のデータセットを確認します。これらのデータセットは PVC とは別に編集でき、音声ファイルを管理するのに便利です。
過去の Pro Voice Clone のデータを再利用する場合は、**Select dataset** タブに切り替えて、以前のデータセットを確認します。これらのデータセットは PVC とは別に編集でき、音声ファイルを管理するのに便利です。
 トレーニングは完了までに 3 時間ほどかかります。トレーニングが成功した場合にのみ料金が発生します。トレーニングが失敗した場合は、`Re-attempt Training` ボタンをクリックして再試行できます。失敗が続く場合は[サポート](mailto:support@cartesia.ai)までお問い合わせください。
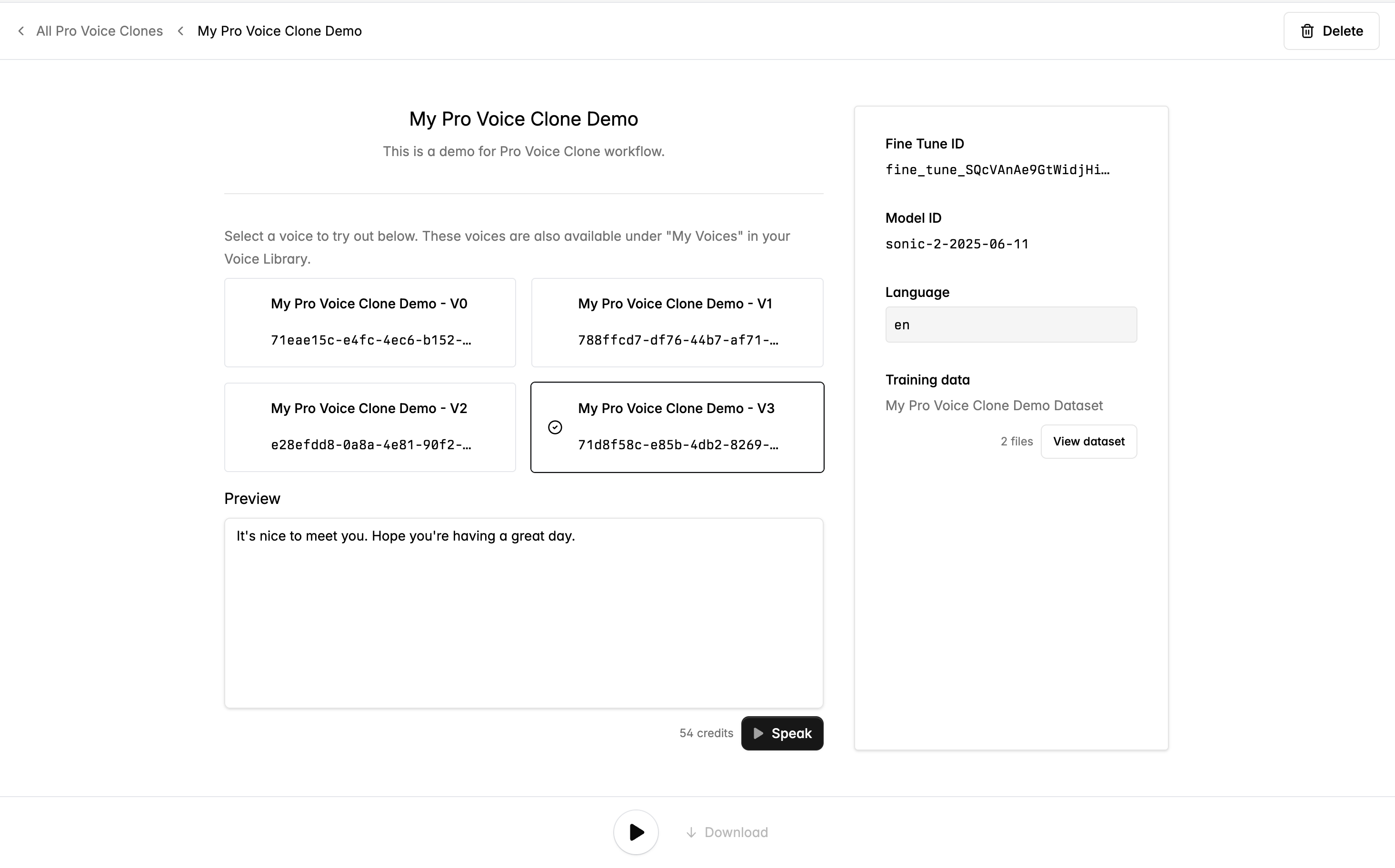
トレーニングが完了すると、データセットの中から異なるソース音声クリップに基づいて 4 つのボイスが自動的に作成されます。これらのボイスは内部的にあなたのファインチューニング済みモデルにリンクされており、リクエストでそのファインチューニング済みモデルのモデル ID を指定したときに使用されます。
ボイスは Voice Library の My Voices からも利用でき、API 経由でも使用できます。
トレーニングは完了までに 3 時間ほどかかります。トレーニングが成功した場合にのみ料金が発生します。トレーニングが失敗した場合は、`Re-attempt Training` ボタンをクリックして再試行できます。失敗が続く場合は[サポート](mailto:support@cartesia.ai)までお問い合わせください。
トレーニングが完了すると、データセットの中から異なるソース音声クリップに基づいて 4 つのボイスが自動的に作成されます。これらのボイスは内部的にあなたのファインチューニング済みモデルにリンクされており、リクエストでそのファインチューニング済みモデルのモデル ID を指定したときに使用されます。
ボイスは Voice Library の My Voices からも利用でき、API 経由でも使用できます。
 **ベースモデルのアップデートに関する注意:**
本番環境で利用可能な最新のベースモデルをファインチューニングしており、その情報は表示されるモデル ID に反映されます。つまり、ファインチューニング済みモデルはこの特定のモデル ID に固定されており、別の `model-id` を使用しても有効化されません。PVC は将来のベースモデル向けに自動的に更新されることはなく、新しいベースモデルごとに再トレーニングが必要です。
新しいデータや最新のベースモデルでファインチューニング済みモデルを再トレーニングすると、再び 1M credits のコストがかかります。
## API 経由で PVC を作成する
API を使用してプログラム的に PVC を作成することもできます。
主要なエンドポイントは次のとおりです。
1. [Datasets: Create](/api-reference/datasets/create) (トレーニングデータを保持)
2. [Datasets: Upload file](/api-reference/datasets/upload-file) (トレーニングデータをアップロード)
3. [Fine Tunes: Create](/api-reference/fine-tunes/create) (ファインチューニング済みモデルを作成)
4. [Fine Tunes: List Voices](/api-reference/fine-tunes/list-voices) (音声生成に使用できる PVC)
PVC を作成する完全なスクリプトは次のとおりです。
> **前提条件**
>
> 1. **Cartesia API キー**を取得済みであること (`CARTESIA_API_KEY` としてエクスポート)。
> 2. アカウントに少なくとも 1M credits があること。
> 3. 1 つ以上の `.wav` ファイルが入った `samples/` というフォルダがあること。
```python lines theme={null}
"""
End-to-end Pro Voice Cloning example.
Steps
-----
1. Create a dataset.
2. Upload audio files from samples/ to the dataset.
3. Kick off a fine-tune from that dataset.
4. Poll until fine-tune is completed.
5. Get the voices produced by the fine-tune.
"""
import os
import time
from pathlib import Path
import requests
API_BASE = "https://api.cartesia.ai"
API_HEADERS = {
"Cartesia-Version": "2025-04-16",
"Authorization": f"Bearer {os.environ['CARTESIA_API_KEY']}",
}
def create_dataset(name: str, description: str) -> str:
"""POST /datasets → dataset id."""
res = requests.post(
f"{API_BASE}/datasets",
headers=API_HEADERS,
json={"name": name, "description": description},
)
res.raise_for_status()
return res.json()["id"]
def upload_file_to_dataset(dataset_id: str, path: Path) -> None:
"""POST /datasets/{dataset_id}/files (multipart/form-data)."""
with path.open("rb") as fp:
res = requests.post(
f"{API_BASE}/datasets/{dataset_id}/files",
headers=API_HEADERS,
files={"file": fp, "purpose": (None, "fine_tune")},
)
res.raise_for_status()
def create_fine_tune(dataset_id: str, *, name: str, language: str, model_id: str) -> str:
"""POST /fine-tunes → fine-tune id."""
body = {
"name": name,
"description": "Pro Voice Clone demo",
"language": language,
"model_id": model_id,
"dataset": dataset_id,
}
res = requests.post(f"{API_BASE}/fine-tunes", headers=API_HEADERS, json=body, timeout=60)
res.raise_for_status()
return res.json()["id"]
def wait_for_fine_tune(ft_id: str, every: float = 10.0) -> None:
"""Poll GET /fine-tunes/{id} until status == completed."""
start = time.monotonic()
while True:
res = requests.get(f"{API_BASE}/fine-tunes/{ft_id}", headers=API_HEADERS)
res.raise_for_status()
status = res.json()["status"]
print(f"fine-tune {ft_id} -> {status}. Elapsed: {time.monotonic() - start:.0f}s")
if status == "completed":
return
if status == "failed":
raise RuntimeError(f"fine-tune ended with status={status}")
time.sleep(every)
def list_voices(ft_id: str) -> list[dict]:
"""GET /fine-tunes/{id}/voices → list of voices."""
res = requests.get(f"{API_BASE}/fine-tunes/{ft_id}/voices", headers=API_HEADERS)
res.raise_for_status()
return res.json()["data"]
if __name__ == "__main__":
# Create the dataset
DATASET_ID = create_dataset("PVC demo", "Samples for a Pro Voice Clone")
print("Created dataset:", DATASET_ID)
# Upload .wav files to the dataset
for wav_path in Path("samples").glob("*.wav"):
upload_file_to_dataset(DATASET_ID, wav_path)
print(f"Uploaded {wav_path.name} to dataset {DATASET_ID}")
# Ask for confirmation before kicking off the fine-tune
confirmation = input(
"Are you sure you want to start the fine-tune? It will cost 1M credits upon successful completion (yes/no): "
)
if confirmation.lower() != "yes":
print("Fine-tuning cancelled by user.")
exit()
# Kick off the fine-tune
FINE_TUNE_ID = create_fine_tune(
DATASET_ID,
name="PVC demo",
language="en",
model_id="sonic-2",
)
print(f"Started fine-tune: {FINE_TUNE_ID}")
# Wait for training to finish
wait_for_fine_tune(FINE_TUNE_ID)
print("Fine-tune completed!")
# Fetch the voices created by the fine-tune
voices = list_voices(FINE_TUNE_ID)
print("Voices IDs:")
for voice in voices:
print(voice["id"])
```
**ベースモデルのアップデートに関する注意:**
本番環境で利用可能な最新のベースモデルをファインチューニングしており、その情報は表示されるモデル ID に反映されます。つまり、ファインチューニング済みモデルはこの特定のモデル ID に固定されており、別の `model-id` を使用しても有効化されません。PVC は将来のベースモデル向けに自動的に更新されることはなく、新しいベースモデルごとに再トレーニングが必要です。
新しいデータや最新のベースモデルでファインチューニング済みモデルを再トレーニングすると、再び 1M credits のコストがかかります。
## API 経由で PVC を作成する
API を使用してプログラム的に PVC を作成することもできます。
主要なエンドポイントは次のとおりです。
1. [Datasets: Create](/api-reference/datasets/create) (トレーニングデータを保持)
2. [Datasets: Upload file](/api-reference/datasets/upload-file) (トレーニングデータをアップロード)
3. [Fine Tunes: Create](/api-reference/fine-tunes/create) (ファインチューニング済みモデルを作成)
4. [Fine Tunes: List Voices](/api-reference/fine-tunes/list-voices) (音声生成に使用できる PVC)
PVC を作成する完全なスクリプトは次のとおりです。
> **前提条件**
>
> 1. **Cartesia API キー**を取得済みであること (`CARTESIA_API_KEY` としてエクスポート)。
> 2. アカウントに少なくとも 1M credits があること。
> 3. 1 つ以上の `.wav` ファイルが入った `samples/` というフォルダがあること。
```python lines theme={null}
"""
End-to-end Pro Voice Cloning example.
Steps
-----
1. Create a dataset.
2. Upload audio files from samples/ to the dataset.
3. Kick off a fine-tune from that dataset.
4. Poll until fine-tune is completed.
5. Get the voices produced by the fine-tune.
"""
import os
import time
from pathlib import Path
import requests
API_BASE = "https://api.cartesia.ai"
API_HEADERS = {
"Cartesia-Version": "2025-04-16",
"Authorization": f"Bearer {os.environ['CARTESIA_API_KEY']}",
}
def create_dataset(name: str, description: str) -> str:
"""POST /datasets → dataset id."""
res = requests.post(
f"{API_BASE}/datasets",
headers=API_HEADERS,
json={"name": name, "description": description},
)
res.raise_for_status()
return res.json()["id"]
def upload_file_to_dataset(dataset_id: str, path: Path) -> None:
"""POST /datasets/{dataset_id}/files (multipart/form-data)."""
with path.open("rb") as fp:
res = requests.post(
f"{API_BASE}/datasets/{dataset_id}/files",
headers=API_HEADERS,
files={"file": fp, "purpose": (None, "fine_tune")},
)
res.raise_for_status()
def create_fine_tune(dataset_id: str, *, name: str, language: str, model_id: str) -> str:
"""POST /fine-tunes → fine-tune id."""
body = {
"name": name,
"description": "Pro Voice Clone demo",
"language": language,
"model_id": model_id,
"dataset": dataset_id,
}
res = requests.post(f"{API_BASE}/fine-tunes", headers=API_HEADERS, json=body, timeout=60)
res.raise_for_status()
return res.json()["id"]
def wait_for_fine_tune(ft_id: str, every: float = 10.0) -> None:
"""Poll GET /fine-tunes/{id} until status == completed."""
start = time.monotonic()
while True:
res = requests.get(f"{API_BASE}/fine-tunes/{ft_id}", headers=API_HEADERS)
res.raise_for_status()
status = res.json()["status"]
print(f"fine-tune {ft_id} -> {status}. Elapsed: {time.monotonic() - start:.0f}s")
if status == "completed":
return
if status == "failed":
raise RuntimeError(f"fine-tune ended with status={status}")
time.sleep(every)
def list_voices(ft_id: str) -> list[dict]:
"""GET /fine-tunes/{id}/voices → list of voices."""
res = requests.get(f"{API_BASE}/fine-tunes/{ft_id}/voices", headers=API_HEADERS)
res.raise_for_status()
return res.json()["data"]
if __name__ == "__main__":
# Create the dataset
DATASET_ID = create_dataset("PVC demo", "Samples for a Pro Voice Clone")
print("Created dataset:", DATASET_ID)
# Upload .wav files to the dataset
for wav_path in Path("samples").glob("*.wav"):
upload_file_to_dataset(DATASET_ID, wav_path)
print(f"Uploaded {wav_path.name} to dataset {DATASET_ID}")
# Ask for confirmation before kicking off the fine-tune
confirmation = input(
"Are you sure you want to start the fine-tune? It will cost 1M credits upon successful completion (yes/no): "
)
if confirmation.lower() != "yes":
print("Fine-tuning cancelled by user.")
exit()
# Kick off the fine-tune
FINE_TUNE_ID = create_fine_tune(
DATASET_ID,
name="PVC demo",
language="en",
model_id="sonic-2",
)
print(f"Started fine-tune: {FINE_TUNE_ID}")
# Wait for training to finish
wait_for_fine_tune(FINE_TUNE_ID)
print("Fine-tune completed!")
# Fetch the voices created by the fine-tune
voices = list_voices(FINE_TUNE_ID)
print("Voices IDs:")
for voice in voices:
print(voice["id"])
```