なぜ Pro Voice Cloning を使うのか?
Professional Voice Clone (PVC) は、あなたのデータで TTS モデルをファインチューニングして作成される音声で、アクセント、話し方、音質を含めて聞き取ったボイスをほぼ忠実に再現できます。 Instant Voice Cloning と比較して、Pro Voice Cloning は数時間に及ぶスタジオ品質の音声データの細かなニュアンスまで捉えることができます。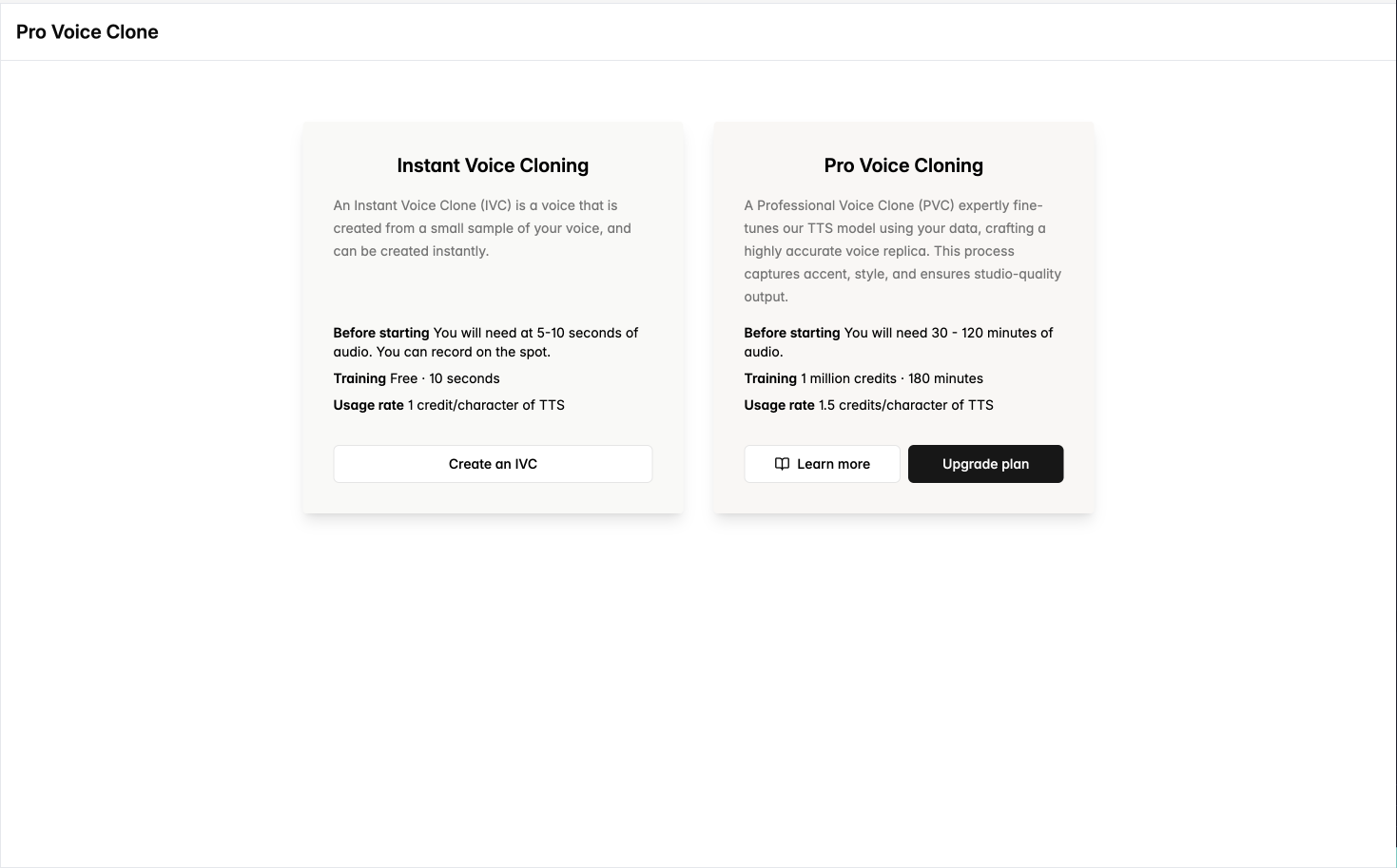
概要
Pro Voice Cloning は、Startup プラン以上の Cartesia サブスクリプションをお持ちの方にご利用いただけます。インスタントクローンと比べてより多くのデータを活用し、非常に精度の高いボイスクローンを作成できます。
Pro Voice Clone を作成すると、Cartesia はまずあなたのデータでモデルをファインチューニングし、その後、データから選ばれたクリップをもとにボイスを作成します。これらのボイスはファインチューニング済みモデルに紐づけられ、テキスト読み上げの際にそれらのボイスとともに自動的に使用されます。
プレイグラウンドから PVC を作成する
プレイグラウンドの Pro Voice Clone ページで PVC を作成できます。ここでは、ご自身のすべての PVC と、そのステータス (Draft、Failed、Training、Completed など) も確認できます。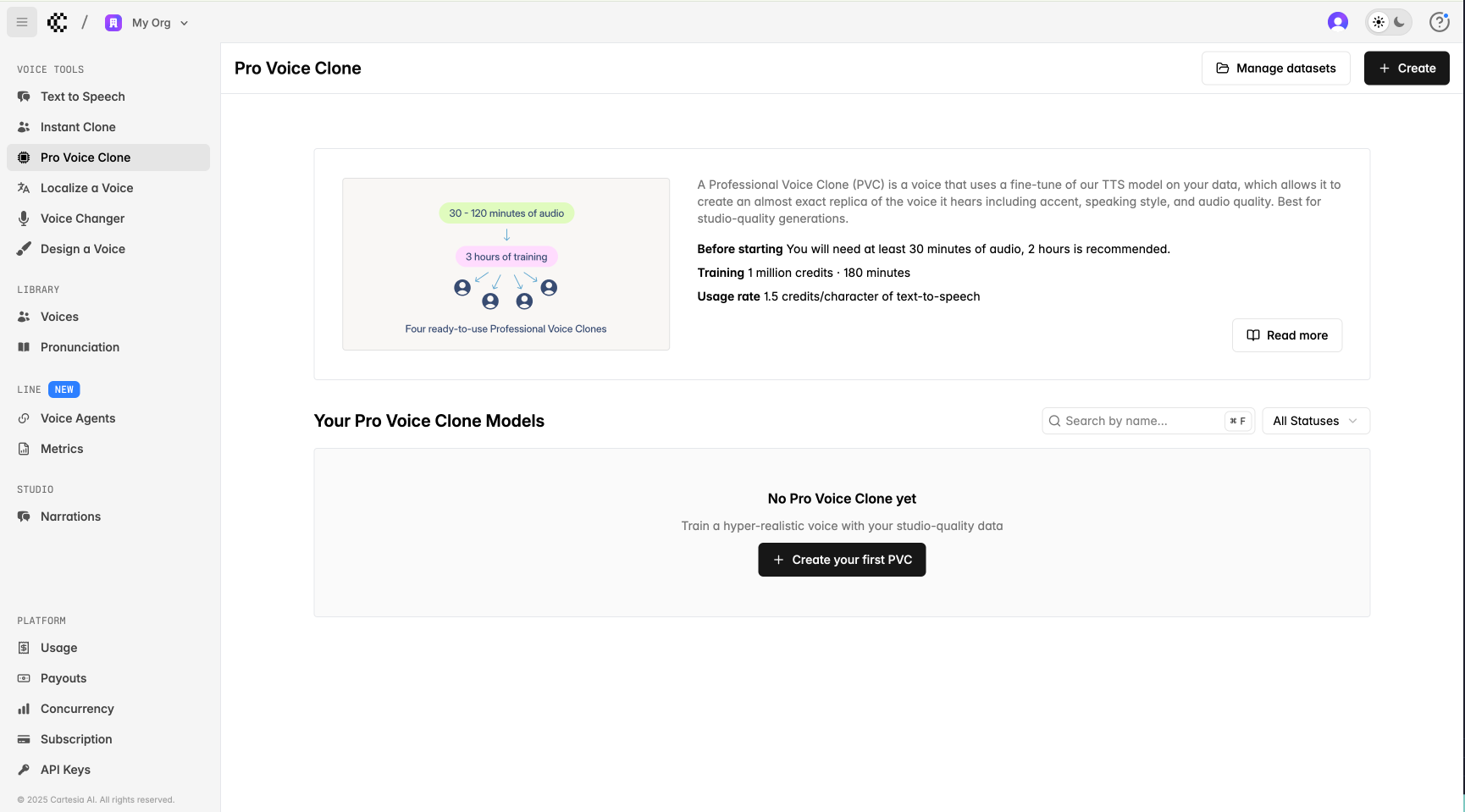
1
データを準備する
フォームに記入して Pro Voice Clone を作成します。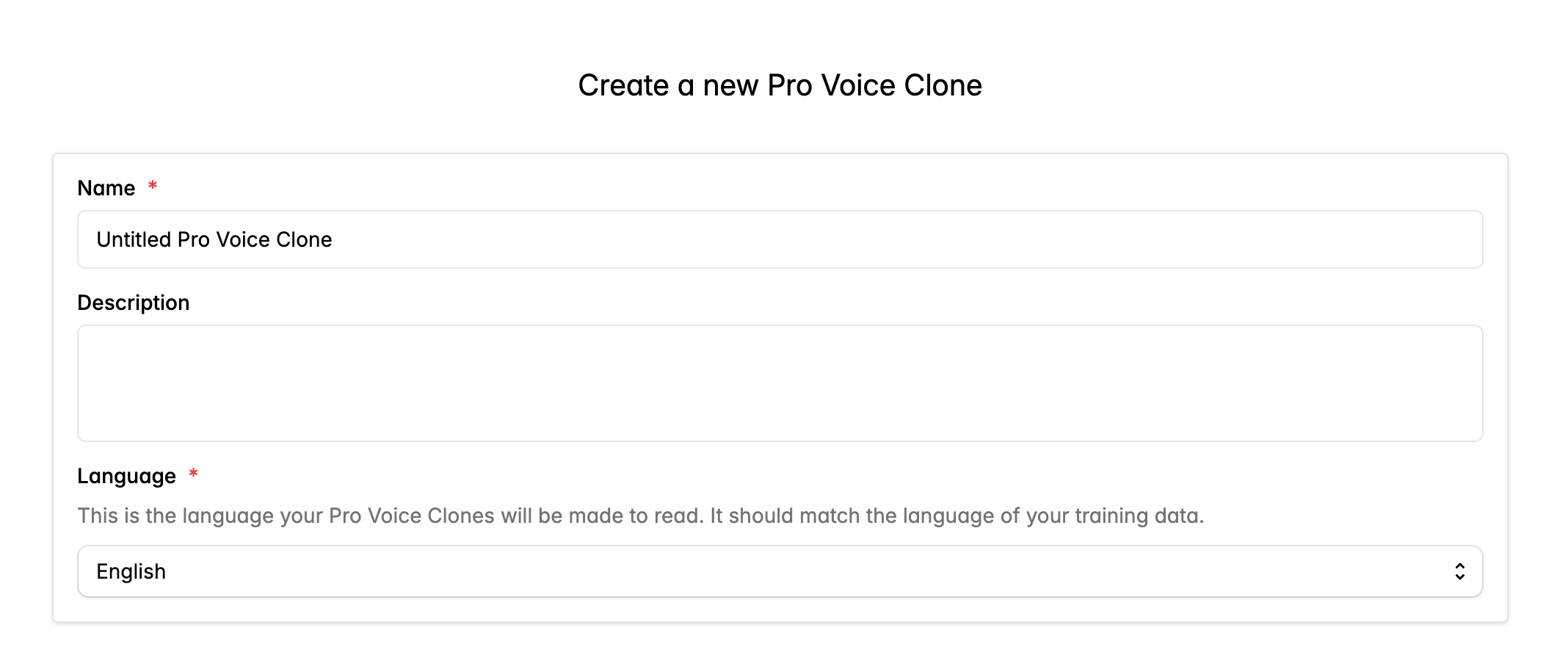
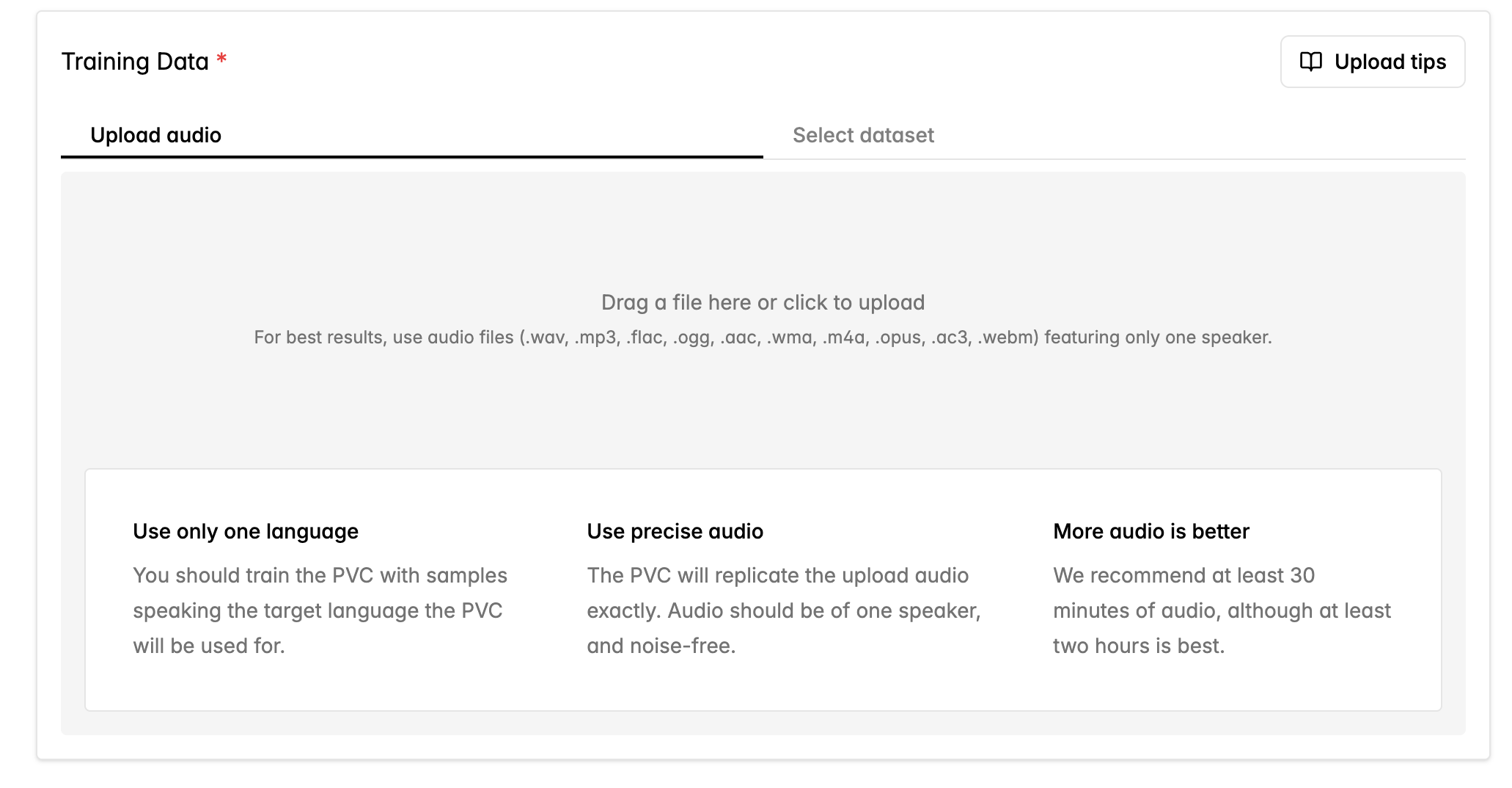
- .wav
- .mp3
- .flac
- .ogg
- .oga
- .ogx
- .aac
- .wma
- .m4a
- .opus
- .ac3
- .webm
2
モデルをトレーニングする
トレーニングは完了までに 3 時間ほどかかります。トレーニングが成功した場合にのみ料金が発生します。トレーニングが失敗した場合は、
Re-attempt Training ボタンをクリックして再試行できます。失敗が続く場合はサポートまでお問い合わせください。3
ボイスをテストする
トレーニングが完了すると、データセットの中から異なるソース音声クリップに基づいて 4 つのボイスが自動的に作成されます。これらのボイスは内部的にあなたのファインチューニング済みモデルにリンクされており、リクエストでそのファインチューニング済みモデルのモデル ID を指定したときに使用されます。ボイスは Voice Library の My Voices からも利用でき、API 経由でも使用できます。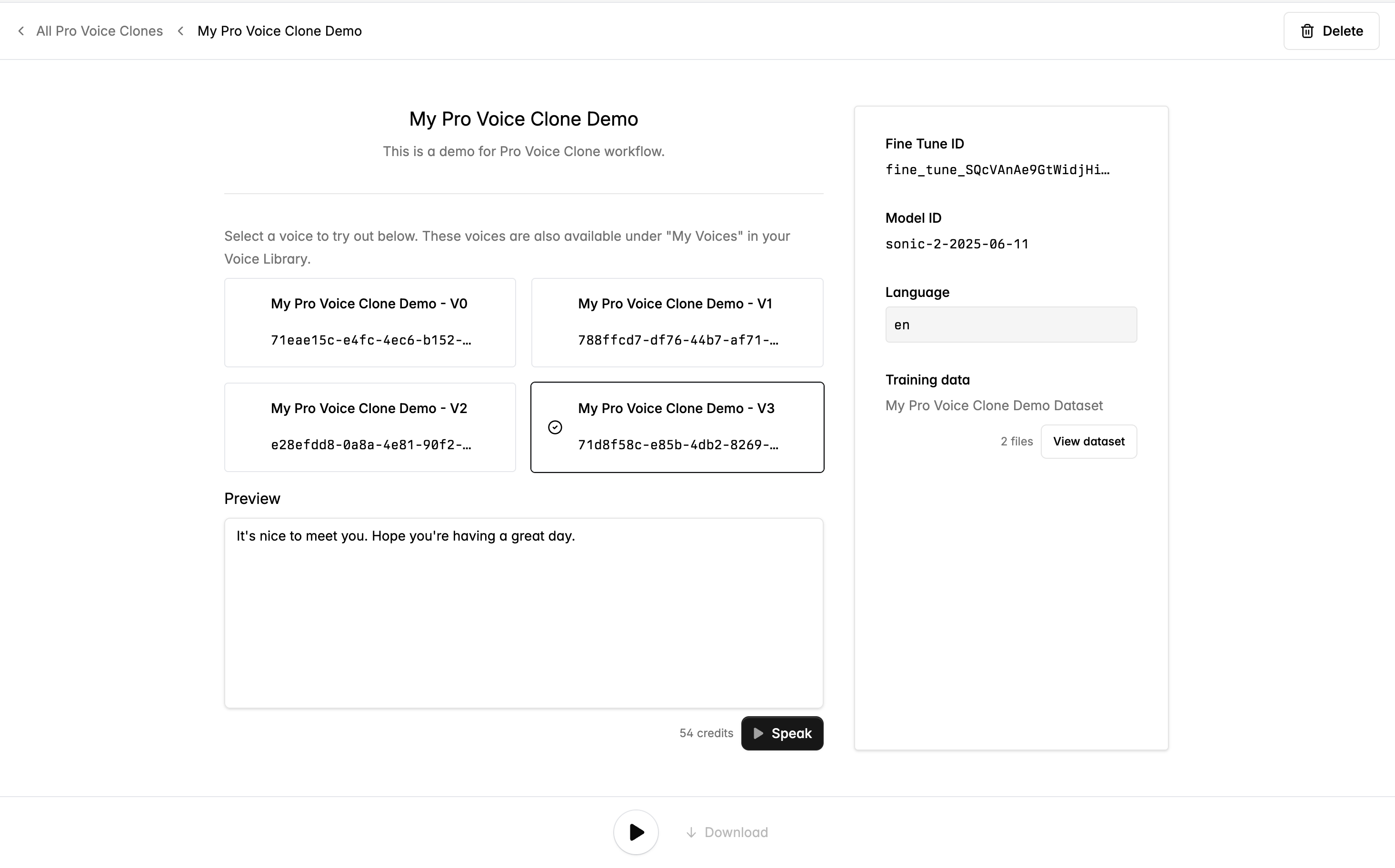
model-id を使用しても有効化されません。PVC は将来のベースモデル向けに自動的に更新されることはなく、新しいベースモデルごとに再トレーニングが必要です。
新しいデータや最新のベースモデルでファインチューニング済みモデルを再トレーニングすると、再び 1M credits のコストがかかります。API 経由で PVC を作成する
API を使用してプログラム的に PVC を作成することもできます。 主要なエンドポイントは次のとおりです。- Datasets: Create (トレーニングデータを保持)
- Datasets: Upload file (トレーニングデータをアップロード)
- Fine Tunes: Create (ファインチューニング済みモデルを作成)
- Fine Tunes: List Voices (音声生成に使用できる PVC)
前提条件
- Cartesia API キーを取得済みであること (
CARTESIA_API_KEYとしてエクスポート)。- アカウントに少なくとも 1M credits があること。
- 1 つ以上の
.wavファイルが入ったsamples/というフォルダがあること。